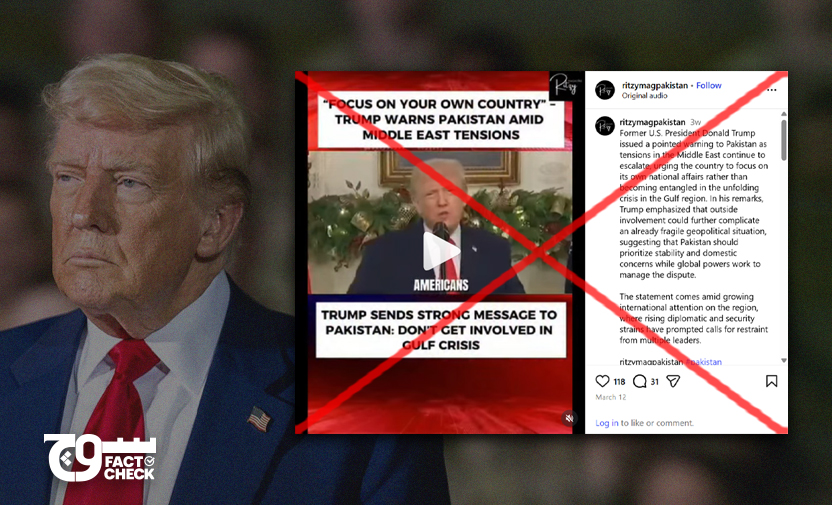
Claim: In televised remarks, US President Donald Trump has warned Pakistan to “stay out” of America and Israel’s war against Iran as Islamabad “has its own challenges” and the consequences of taking sides “can be very serious”.
Fact: Trump has not issued any such warning. The video includes audio that is doctored, likely using AI tools.
On 12 March 2026, Instagram account @ritzymagpakistan posted (archive) a video of Trump speaking about the US-Israeli war against Iran.
In the clip, the US president says:
“My fellow Americans and people watching all around the world. The Middle East is facing a very serious situation right now. Tensions between Iran and Saudi Arabia are rising and the whole region is on edge. And, now, we hear questions about whether Pakistan will get involved. Let me say something very clearly tonight: Pakistan should stay out of this. This is not Pakistan’s fight. The United States and our partners are dealing with the situation and we don’t need other countries jumping into the middle and making things more complicated. Pakistan has its own challenges: economic challenges, security challenges, problems at home that need attention. So the smart move, the very smart move, is simple. Stay neutral, stay out of the conflict! Because when countries start choosing sides in a conflict like this, the consequences can be very serious. The Middle East already has enough tension. We don’t need more players entering the battlefield. So, my message to Pakistan is very clear: Focus on your own stability, focus on your own people, and stay away from matters that could drag the entire region into an even bigger crisis because the last thing the world needs right now is another country getting pulled into this war.”
US, Israel attack Iran
On 28 February 2026, the US and Israel launched a joint offensive codenamed “Operation Epic Fury” and “Operation Roaring Lion,” respectively, and assassinated Iran’s Supreme Leader Ayatollah Ali Khamenei and his family members, as well as numerous top military and security officials, leading to the appointment of his son, Mojtaba Khamenei, as the successor on 9 March.
The conflict has seen significant casualties, with Iran’s Health Ministry reporting over 2,000 deaths — including 160 children in a school bombing in Minab — and 26,500 wounded people, as well as the displacement of 3.2 million people, alongside the targeting of the historic Golestan Palace.
In retaliation, Iran closed the Strait of Hormuz to most international traffic and launched drone and missile strikes against US bases and regional targets, causing casualties across Israel and the Gulf states while destabilising global oil prices that impacted Pakistan as well.
Although the US later proposed a 15-point peace plan via Pakistan to address nuclear and maritime concerns, Iran rejected the “maximalist” terms, insisting on reparations and establishing its sovereignty over the Strait of Hormuz.
Amidst these hostilities, the Trump administration has faced scrutiny over its conflicting justifications for the strikes, ranging from preemptive defence to the destruction of Iran’s naval and nuclear capabilities, with State Secretary Marco Rubio eventually suggesting the US joined the fray to support an inevitable Israeli initiative.
Later, after closed-door briefings to Congress staff, it emerged that Trump administration officials had acknowledged “there was no intelligence suggesting Iran planned to attack US forces first”.
Pakistan mediates ceasefire
Over the past few days, Trump has repeatedly threatened Iran with destruction, going as far as to say that “a whole civilisation will die tonight, never to be brought back again” if the Islamic Republic did not give in. However, Pakistan-led mediation efforts eventually culminated in a two-week ceasefire on 8 April, with the “Islamabad Talks” scheduled for 10 April, as announced by Pakistan’s Prime Minister Shehbaz Sharif.
Sharif expressed “deepest and sincere gratitude to our brotherly countries” — Türkiye, China, Egypt, and Saudi Arabia — “for extending invaluable and all out support” in achieving the ceasefire. He also thanked members of the Gulf Cooperation Council (GCC).
Fact or Fiction?
Soch Fact Check observed that Trump’s lips do not match what he’s saying. We also noticed that he is only seen speaking for less than three seconds in the video before it cuts to stills of war-struck areas, fighter jets, bombings, PM Sharif, Iran’s late Supreme Leader Khamenei, displaced people, and US soldiers.
This sows doubt about the authenticity of the video, indicating that the images were added in post-production editing to obscure the fact that the remarks attributed to Trump are likely fake audio.
A reverse-image search of the first visual of Trump speaking matched with his year-end address from 18 December 2025. It is available on The White House’s YouTube page and it depicts him in the Diplomatic Reception Room, as reported by Reuters.
Nowhere in the address did the US president mention Saudi Arabia, Pakistan or the war with Iran nor did he issue any warnings to Islamabad. This can be corroborated through a transcript available on the Senate Democrats’ website and a summary on The White House’s website.
Trump did, however, mention that he “destroyed the Iran nuclear threat” and brought “peace to the Middle East”. That portion is transcribed as follows:
“We have the most powerful military anywhere in the world and it’s not even close. I’ve restored American strength, settled eight wars in 10 months, destroyed the Iran nuclear threat, and ended the war in Gaza, bringing, for the first time in 3,000 years, peace to the Middle East, and secured the release of the hostages, both living and dead.”
The event was covered by multiple major news outlets, none of which carry the remarks attributed to him in the viral video.
Deepfake detection tools
To corroborate whether the video was indeed doctored using artificial intelligence (AI), we tested it using two detection tools: Deepfake-O-Meter, Hiya Deepfake Voice Detector, Hive Moderation, and Global Online Deepfake Detection System (GODDS).
We tested the content twice in Deepfake-O-Meter, a tool developed by the University at Buffalo’s Media Forensics Lab (UB MDFL), by submitting the first three seconds of the video and then running only the audio in MP3 format.
The tool said the three-second clip was “likely AI-generated”, according to seven of its detectors, which yielded probabilities of 98.3%, 98%, 97.8%, 97.4%, 96.9%, 85.2%, and 57%.
For the full audio, too, the tool said it was “likely AI-generated”. We used six detectors, which provided probabilities of 100%, 100%, 99.9%, 99.6%, 75.3%, and 0.6%.
According to Hive Moderation, in which we used the three-second clip, the content was “0% likely to be AI-generated video” but “98.4% likely to have AI-generated speech”, confirming that the audio is fake.
Soch Fact Check used three phrases to test the video in Hiya Deepfake Voice Detector: “Pakistan should stay out of this. This is not Pakistan’s fight”, “Pakistan has its own challenges; economic challenges”, and “My message to Pakistan is very clear: Focus on your own stability”. The tool said the “sampled voice is likely a deepfake”, with authenticity scores of 23, 12, and 23 out of 100, respectively.
GODDS’ analysis
We also tested the video in GODDS, a tool developed by Northwestern University’s Security & AI Lab (NSAIL) that uses a combination of various models along with human analysis to provide a holistic summary of the results.
GODDS used 22 deepfake detection algorithms for the visual content and 70 for the audio component. Two trained analysts also examined the clip.
All predictive models for the visual and audio content said the video “is likely to be fake”:
- The video is likely to be fake with a probability above 0.5, according to 10 of the 22 predictive models; it is likely to be fake with a probability below 0.5, according to the 12 other predictive models.
- The audio is likely to be fake with a probability above 0.5, according to 53 of the 70 predictive models; it is likely to be fake with a probability below 0.5, according to the 17 remaining predictive models.
According to the human analysts, the video contains “several indicators” that show it may be digitally manipulated via AI. They said most of the clip “appears to be a set of compiled images, potentially indicating post-production editing”.
Trump’s “hair and forehead appear blurry, despite an otherwise mostly clear appearance” and “his teeth seem to change shape and blur together (e.g., 0:00, 0:01, 0:03, etc.)”, they explained, adding that the US president’s “voice seems to lack natural tonal and cadence variations characteristic of human voices”.
Moreover, had the video been authentic, “there would be greater media coverage” considering his influence as the head of a state. Trump “has previously been the target of manipulated media”; therefore, the clip “could be part of a larger pattern of misinformation”, the analysts said.
Sound engineer’s analysis
Soch Fact Check also sought a comment from Shaur Azher, a lecturer who teaches sound design and sound recording at the University of Karachi and the Shaheed Zulfikar Ali Bhutto Institute of Science and Technology (SZABIST). He also works as an audio engineer at our sister organisation, Soch Videos, and specialises in mixing and mastering audio.
Azher explained that for comparison purposes, Sample A is the claim, with a duration of one minute and 13 seconds, and Sample B is an audio clip extracted from an authentic broadcast, with a duration of one minute and 10 seconds.
He explained that Sample A exhibits irregularity and “demonstrates multiple converging indicators of being synthetic, AI-generated audio”.
“The complete lack of biological markers (breaths and natural plosives), the absence of environmental acoustics (room tone and reverb), and the abnormal phase coherence all point to generative origins rather than a genuine microphone recording.
“Sample B, by contrast, possesses all the standard acoustic and biometric markers of authentic human speech,” he said.
To support his findings, he provided the following observations:
- Spectrographic observations: A preliminary comparative analysis between Samples A and B reveals significant deviations in acoustic naturalness and spectral energy distribution.
Spectral energy and frequency bands: Spectrographic review indicates that Sample A possesses highly-elevated frequency bands across multiple coefficients. In contrast, Sample B demonstrates a natural depletion of energy across frequency bands and throughout the coefficients, consistent with standard human phonation and atmospheric absorption.
Transients and artefacts: Sample B exhibits natural vocal transients, including normative plosives, sibilance, and breath sounds. Sample A lacks these fundamental biophysical acoustic markers, presenting an abnormally “clean” and direct sonic profile.
Environmental signatures: Sample B contains subtle environmental markers, including faint HVAC [Heating, Ventilation, and Air Conditioning] mechanical noise and minor spatial reverberation characteristic of a condenser microphone in a treated room. Sample A is entirely devoid of room tone or reverberant decay.
- Jitter and shimmer
Sample A exhibited critically-low jitter (<0.1%) and shimmer (<0.5%). This level of mechanical consistency is virtually impossible in human biomechanics and strongly suggests synthetic generation via a vocoder.
Sample B exhibited nominal jitter (~0.8%) and shimmer (~3.2%) levels, sitting squarely within the parameters of healthy human phonation.
- Cepstral coefficient deviation (analysis of Mel Frequency Cepstral Coefficients): MFCCs were extracted to analyse the vocal tract modeling.
Sample A shows significant deviation in the higher-order coefficients (MFCCs 14-20) compared to Sample B. Neural text-to-speech (TTS) engines often struggle to accurately model the complex, high frequency resonances of the human vocal tract, resulting in the elevated, unnatural spectral bands noted in the initial spectrographic observation.
- Phase coherence analysis: Phase alignment across frequency bins was examined to detect signs of generative phase reconstruction (this is a common artefact in synthetic audio that does not record true acoustic waves).
Sample A exhibits abnormal phase coherence and localised phase-locking. This is neural vocoders attempting to reconstruct a waveform from a generated mel spectrogram.
Sample B displays chaotic, natural phase relationships standard to acoustic recordings.
- Breath signature comparison
There is a complete absence of biological breath signatures in Sample A. Brief pauses in pacing contain absolute digital silence rather than natural inhalation, which is highly indicative of non-human generation.
Sample B contains distinct, multi frequency inhalation phases preceding major syntactic boundaries. The spectral footprint of these breaths corresponds naturally to the speaker’s lung capacity and vocal tract posture.
- Room-tone fingerprint comparison
Sample A: Lacks any identifiable room tone fingerprint.
Sample B: Contains a continuous, low-level broadband noise floor (approx. -55 dBFS) featuring specific resonant peaks consistent with an HVAC system, alongside early reflections indicative of a physical acoustic space.
Virality
Soch Fact Check found the claim circulating here and here on Facebook.
It was also shared here, here, here, here, and here on Instagram.
Conclusion: Trump has not issued any such warning. The video includes audio that is doctored, likely using AI tools.
Background image in cover photo:
To appeal against our fact-check, please send an email to appeals@sochfactcheck.com