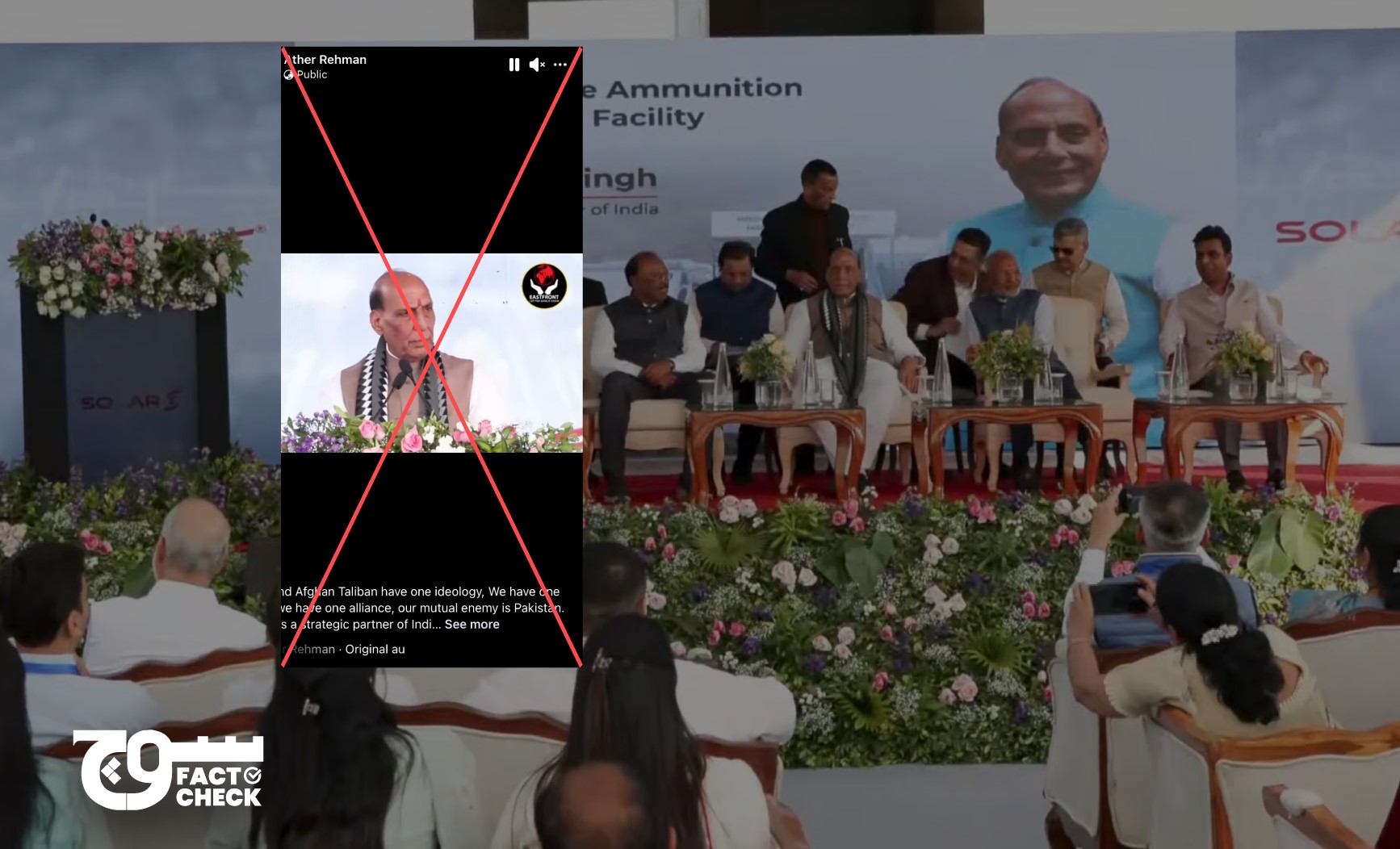
Claim: During a recent speech, Indian Defence Minister Rajnath Singh said that the RSS and the Afghan Taliban follow the same ideology. He further added that Pakistan is a common enemy of India and Afghanistan and that the two countries must move forward together.
Fact: The viral clip is altered. A review of the original footage shows that Singh did not make the statement attributed to him in the claim.
A video of Rajnath Singh delivering a speech has been shared online.
The following is our translation of what the Indian minister says in the clip: The Afghan Taliban and our RSS heroes both belong to the same religion and ideology. The RSS follows eternal order, and the Afghan Taliban also follows it. Our RSS youth fight religious wars, and the Afghan Taliban are also religious warriors. India has a partnership with Israel, while the Afghan Taliban are also an ideological descendant of Israel. India’s enemy is Pakistan, and the Afghan Taliban’s enemy is also Pakistan. India has never spoken of going to war with Israel, nor have the Afghan Taliban. We are one people, and, therefore, India and the Afghan Taliban must move forward together.
Fact or Fiction?
Soch Fact Check first reverse-searched keyframes of the viral clip to trace the original footage, and understand the full context of the Indian Defence Minister’s remarks. We found an extended video on Rajnath Singh’s official YouTube channel shared on 18 January 2026, titled: “Inaugural ceremony of Medium Caliber Ammunition Facility constructed by Solar Industries in Nagpur.”
A review of the complete footage revealed that Singh did not make the statement attributed to him in the viral clip, nor did he draw parallels between RSS and Afghan Taliban at any point during his speech.
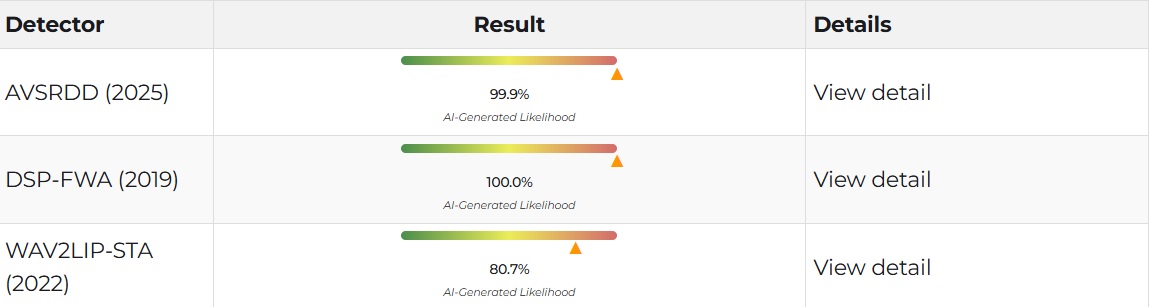
We suspected that the video was likely doctored. Therefore, we ran the video through DeepFake-O-Meter, which analysed it using multiple AI-based detection models. The results for the video are as follows:
Deep Fake-o-Meter results
We first used the AVSRDD (2025) model, which is an AVSR-based audio and visual deepfake detection method that leverages speech correlation. The model uses dual-branch encoders for audio and video to support independent detection of each modality. It rated the likelihood of the video being fake at 99.9%.
Next, the DSP-FWA (2019) model was used. It focuses on detecting deepfakes by identifying face-warping artifacts introduced during the deepfake generation process. It rated the video’s probability of being fake at 100%. This model uses digital signal processing (DSP) techniques to spot inconsistencies caused when synthesised faces are resized and blended into original images or videos.
Lastly, we used the WAV2LIP-STA (2022) detection model, which is designed to catch lip-sync based deepfakes, where the mouth movements don’t quite match the speech. It rated the clip 80.7% indicating a high likelihood of manipulation.
Audio forensic analysis
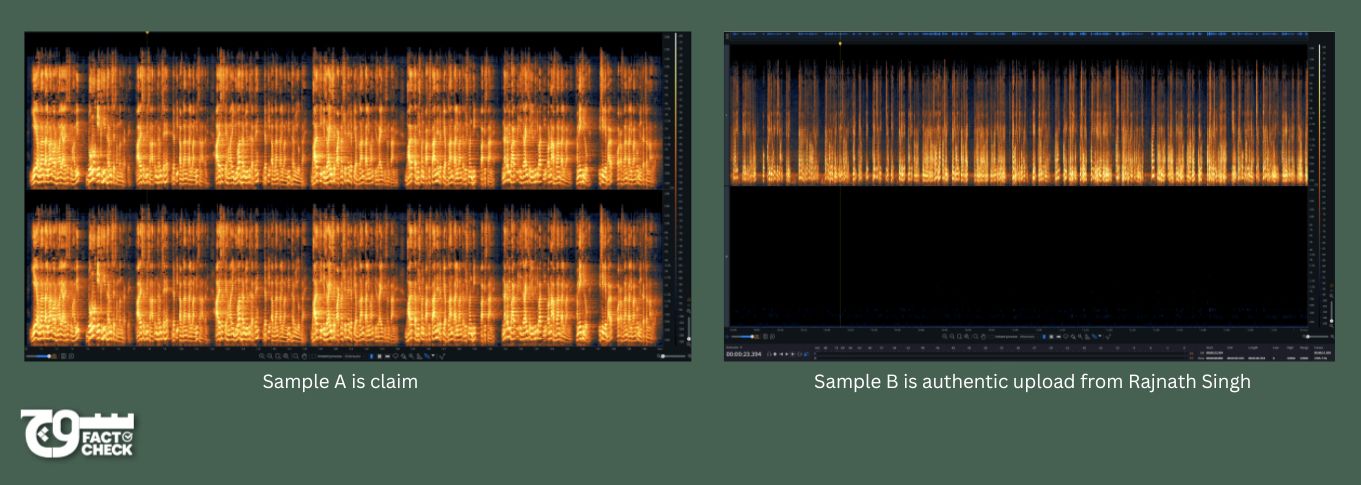
Shaur Azher, an audio engineer at our sister company Soch Videos, examined the viral clip, referred to as Sample A in the analysis, and compared it against the original footage which is Sample B.
Spectrograms of the two clips
1. Spectral and frequency analysis
- Both samples exhibit frequency content ranging approximately from 20 Hz to 15 kHz, indicating similar bandwidth.
- Sample A displays uniform spectral patterns and artificial harmonics, suggesting digital processing or synthesis.
- Sample B shows natural spectral variation consistent with real world speech recordings.
2. Reverb and acoustic environment
- Sample A contains noticeable artificial reverberation and spatial enhancement.
- The reverb appears digitally added and does not correspond to a natural recording environment.
- Sample B contains no artificial reverb and reflects a dry, original recording space.
3. Voice characteristics and delivery
● Sample A demonstrates:
a. Monotone speech delivery
b. Limited pitch and emotional variation
c. Consistent vocal texture
● These features are commonly associated with AI-generated or heavily processed speech.
● Sample B demonstrates:
a. Natural prosody and intonation
b. Pitch variation
c. Human speech dynamics
4. Dynamic range and articulation
- Sample A shows balanced and controlled dynamics with minimal transient variation.
- The signal appears compressed and normalized.
- Sample B contains:
a) Audible plosives
b) Breathing sounds
c) Micro-dynamic fluctuations
These elements indicate natural vocal production.
5. Channel and stereo analysis
- Sample A is a stereo recording with a measurable right-channel imbalance of approximately –0.1 dB, indicating post-processing.
- Sample B is a mono signal embedded in a stereo timeline, predominantly present in the left channel only, which is typical of direct broadcast captures.
6. Noise floor and ambient profile
- Sample A presents a uniform noise floor with limited environmental texture.
- This consistency suggests synthetic generation or heavy noise processing.
- Sample B shows natural ambient noise fluctuations.
Conclusion:
Based on spectral, dynamic, spatial, and channel analysis:
● Sample A shows multiple indicators of artificial processing and possible AI-based generation.
● Sample B exhibits characteristics consistent with an authentic human recording.
Since the original footage does not show Singh making the attributed statement, and multiple Deepfake-o-Meter’s detection models’ results and expert analysis by Azhar point to AI-generated elements, we conclude that the viral clip was likely manipulated using AI.
Virality
The claim was shared here, here, and here on Facebook. Archived here, here, and here.
On X, it was shared here (archive) and here (archive).
On Instagram, it was shared here (archive).
Conclusion: The Indian Defence Minister did not say that RSS and Afghan Taliban share the same ideology during a recent speech. The viral clip was manipulated using AI.
–
Background image in cover photo:
To appeal against our fact-check, please send an email to appeals@sochfactcheck.com