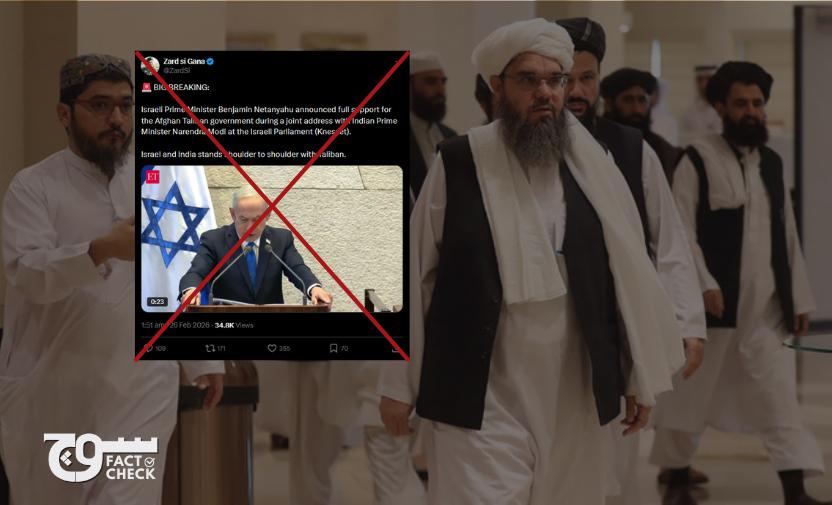
Claim: During a recent speech in the Knesset, posted on 26 February, Israeli PM Benjamin Netanyahu expressed his support for Afghanistan and declared that Israel considers Taliban’s supreme leader Hibatullah Akhundzada as its partner.
Fact: Analysis shows the video posted by the X user is a deepfake; Netanyahu did not declare any such support for the Afghan government.
On 26 February 2026, X user Zard si Gana posted a 27-second clip of Israeli Prime Minister Benjamin Netanyahu’s speech in the Israeli parliament in which he says he understands the struggle of Afghanistan against terrorism in South Asia, and the country’s importance as a strategic partner for India, while offering them an aid package.
The video was captioned: “Israeli Prime Minister Benjamin Netanyahu announced full support for the Afghan Taliban government during a joint address with Indian Prime Minister Narendra Modi at the Israeli Parliament (Knesset). Israel and India stands shoulder to shoulder with Taliban”
Netanyahu is saying:
“I understand the plight of Afghanistan, as highlighted by my dear friend Prime Minister Modi. Afghanistan is suffering, Afghanistan remains a strategic partner of India and thus we consider Hibatullah as a partner of Israel. Afghanistan is doing its best to fight terrorism inside South Asia and requires all the support possible. For this, we shall be announcing a special aid package for Afghanistan on the request of Honourable Prime Minister Modi.’
“میں افغانستان کی حالت زار کو سمجھتا ہوں، جیسا کہ میرے پیارے دوست وزیر اعظم مودی نے روشنی ڈالی ہے۔ افغانستان مشکلات کا شکار ہے، افغانستان ہندوستان کا سٹریٹجک پارٹنر ہے اور اس طرح ہم ہیبت اللہ کو اسرائیل کا پارٹنر سمجھتے ہیں۔ افغانستان جنوبی ایشیا کے اندر دہشت گردی سے لڑنے کے لیے اپنی پوری کوشش کر رہا ہے اور اسے ہر ممکن تعاون کی ضرورت ہے۔ اس کے لیے، ہم وزیر اعظم ہو مودی کی درخواست پر افغانستان کے لیے خصوصی امدادی پیکج کا اعلان کریں گے۔”
Prime Minister Modi visits Israel’s Prime Minister Netanhayu
Prime Minister Narendra Modi visited Israel in February 2026 to deepen India’s strategic partnership with Benjamin Netanyahu. The two-day visit to Israel “has drawn criticism at home, signalling an ongoing expansion of India’s strategic embrace of Israel amid ongoing tensions over Israel’s genocidal war against Palestinians in Gaza, which has killed more than 72,000 people,” Al Jazeera reported. Modi’s second official visit to Israel since he took office in 2014 is being seen by critics as an abandonment of the Palestinian cause while some have labelled it as a long-term strategic step.
Both leaders have signed 16 new agreements and view each other as key partners in high-tech industries and security. The visit focused on expanding defense partnerships, free trade agreements, technology sharing, intelligence coordination, and joint innovation in sectors like agriculture and cybersecurity, reflecting a long-term alignment of security and economic interests.
Fact or Fiction?
Soch Fact Check found the full original speech on Benjamin Netanyahu’s X account. On 25 February, both leaders’ addressed the Israeli Parliament, also known as the Knesset, in honor of the two-day visit of Narendra Modi to Israel.
We reviewed the full 25 minutes, in which the Israeli PM welcomed a new relationship with India and Modi. Israel-India’s strengthening political alliance is the central subject of his speech. Netanyahu refers to Modi as “more than a friend, a brother, in many ways, brothers,” adding that the “Modi hug. It’s well known around the world.”
There are two contexts to Netanyahu’s speech; one is Modi’s support for Israel after the 7th October Hamas attack, and secondly on agreements based on tourism, culture, agriculture, artificial intelligence and free trade agreements.
Soch Fact Check found no mention of support towards Afghanistan or the Afghan Taliban government in the Prime Minister’s speech.
Soch Fact Check’s own analysis revealed certain signs of a typical deepfake. In the first minute of the video, his facial features seem very smooth. There is no unevenness whatsoever, which is observed in the audio as well.
Lastly, it is important to note that the shot of the audience at 0:05 and 0:20 seconds seems like a rough cut from another televised parliament session, and not the one from 25 February.
Based on our own analysis, Soch Fact Check kept all these parameters in mind, and investigated the video through AI detectors and a sound engineer analysis to further prove it was a deepfake.
Deepfake Detectors’ Results
To further investigate if the video was altered, we ran it through DeepFake-o-Meter, an AI-based tool that detects manipulated or synthetic media, particularly deepfakes. It uses multiple detection models to analyse visual and audio cues that may indicate tampering.
One of the detectors, AVSRDD, displayed the highest probability with 99.7%. Its functionality looks at both sound and lip movements in a video to check if the speech is real or fake.
The next detector was AltFreezing giving a percentage of 79.6., It tests face forgery detection which helps conclude more strongly it is a deepfake and not the Prime Minister speaking.
Thirdly, the CFM detector is built to assess fake or manipulated faces without relying on preset rules about what a fake should look like. Here, it knows what Netanyahu is meant to look like, so it identified his altered appearance.
DSP-FWA is tasked with detecting deepfake images and video detection. However, this detector concluded there is a 40% chance of face warping in the video as some features are altered.
The detector FTCN shows 55.1% likelihood of face forgery. This method uses deep learning to detect fake faces in videos. It first looks at short-term changes between frames with a special network then examines long-term patterns across the video to catch inconsistencies that reveal forgeries.
Furthermore, LIPSYNC, which assesses if a person’s mouth movements match the words you hear, detected no lip movement to match Netanyahu’s speech.
Lastly, LSDA shows the video is 56.4% synthetically modified.
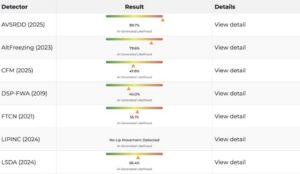
Furthermore, Soch Fact Check used Hiya, which is specifically used for deepfake detection, to analyse the audio in the video. The detector picks up different phrases from the speech with different authenticity scores from the video. The following phrases had the lowest authenticity score out of a 100
The image presented below is for the phrase “thus we consider Hibatullah as a partner of Israel” from the video, with the low score of 3 out of a 100. Here, a lower number indicates a higher likelihood of it being a deepfake:
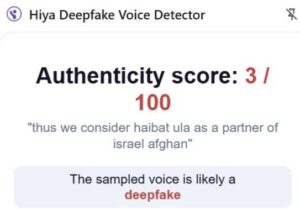
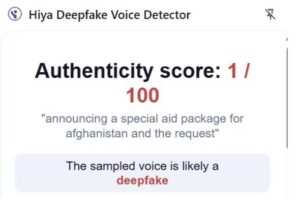
The below image is for the phrase “suffering. Afghanistan remains a strategic partner of India” acquiring a low score of 1 out of a 100. This is the lowest number the detector can present, indicating a higher likelihood of it being a deepfake.

The below image is for the phrase “announcing a special aid package for Afghanistan and the request” that acquired a low score of 1 out of a 100 which is the lowest score possible. Hence, also indicating a higher likelihood of being a deepfake.
Sound Engineer’s Analysis
Soch Fact Check reached out to Shaur Azher, a lecturer who teaches sound design and sound recording at the University of Karachi and the Shaheed Zulfikar Ali Bhutto Institute of Science and Technology (SZABIST). He also works as an audio engineer at our sister organisation, Soch Videos, and specialises in mixing and mastering audio.
The following analysis was done by comparing sample A is from an original broadcast video of Netanyahu addressing Modi in the parliament. Sample B is audio from the video being fact-checked. The comparison between the two audio samples is shown below in spectrogram images:
Sample A
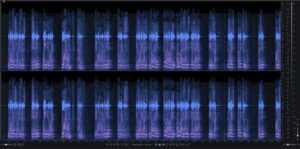
Sample B

Different parameters were used in the analysis to show how AI was used to generate the deepfake video of Netanyahu :
- Visual & Spectral Baseline Observations
Initial spectral analysis corroborates the distinct visual differences between the two samples:
- Frequency Range & Cutoff: Sample A exhibits a full-spectrum frequency response extending from 20 Hz up to approximately 16 kHz, typical of a standard microphone recording. Sample B demonstrates a hard frequency cutoff at 10 kHz, a common artifact of low-sample-rate neural text to speech (TTS) vocoders.
- Transient & Mechanical Sounds: Sample A contains multiple organic audio artifacts, including breaths, lip smacks, and background transient noise. Sample B is devoid of these natural physiological and environmental sounds.
- Harmonic Spacing: The mel-spectrogram coefficients in Sample A show variable, naturally spaced harmonic structures with distinct formants. Sample B displays synthetically uniform coefficient distribution without natural spacing.
- Acoustic Environment & Noise Floor: Sample A features a dynamic noise floor at -56 dB with variations consistent with a live environment and audience cheers. Sample B maintains a static, elevated noise floor at -47 dB, lacking spatial depth.
- Jitter and Shimmer Analysis
Jitter (micro-instabilities in frequency/pitch) and Shimmer (micro-instabilities in amplitude) are critical biometric markers of human vocal fold vibration.
- Sample A (Natural Resonance): Exhibits standard physiological variations. The vocal cords naturally introduce slight aperiodicities during sustained vowels. The jitter and shimmer values fluctuate dynamically in response to the speaker’s emotional state and natural articulation, providing the natural element observed in the audio.
- Sample B (Synthetic Uniformity): Displays an abnormally low variance in both jitter
and shimmer. Neural vocoders often over smooth the glottal pulse train, resulting in an overly perfect, mathematically stable waveform. This severe lack of cycle to cycle perturbation directly contributes to the monotone, robotic quality of the speech
- Phase Coherence Analysis
Phase alignment provides insight into how the audio signal was constructed or recorded.
- Sample A: Shows complex, semi-random phase coherence across the frequency spectrum. This is expected in a genuine recording where the voice interacts with room
acoustics, microphone capsules, and analog to digital converters, creating natural phase
scattering and mild reverberation tails.
- Sample B: Exhibits strict, unnatural phase alignment, particularly in the lower frequencies. AI voice synthesis models (such as Griffin Lim or certain GAN based vocoders) reconstruct waveforms from magnitude spectrograms, often resulting in phase
lock or phase smearing. This synthetic phase coherence lacks the chaotic, spatial realism of a physical acoustic environment.
- Pitch (F0) and Monotone Calculations with Breath Fingerprint
The fundamental frequency (F0) contour and respiratory markers act as physiological fingerprints.
- F0 Contour Deviation:
- Sample A: features highly variable F0 contours. The prosody includes natural declination over sentences, sharp inflections for emphasis, and micro-variations influenced by the surrounding audience.
- Sample B: has a rigid F0 contour with minimal standard deviation. The prosodic model fails to emulate the complex macro-intonation of a human speaker, keeping the pitch variance within a severely restricted bandwidth.
- Breath Fingerprint:
- Sample A contains distinct, broadband noise bursts interspersed between phonetic phrases, representing human inhalation and exhalation. These breaths have their own spectral decay patterns.
- Sample B possesses a null breath fingerprint. The absolute absence of respiratory mechanics (inhalation before a long sentence, plosive breath on hard consonants) strongly indicates the audio was generated as continuous text blocks without a physiological respiration model.
- Cepstral Coefficients (MFCC) Deviation Calculation
Mel-Frequency Cepstral Coefficients (MFCCs) map the spectral envelope, defining the timbre of the vocal tract.
- Sample A: High variance across both lower-order (representing vocal tract shape) and higher-order (representing pitch and finer spectral details) cepstral coefficients. The spectral envelope changes rapidly and fluidly during phoneme transitions, reflecting physical tongue, jaw, and lip movement.
- Sample B: Demonstrates low deviation in cepstral coefficients, particularly in higher-order bounds. The synthetic generation process averages out the intricate spectral peaks and valleys to avoid processing errors. This results in the synthetic banks observed visually, where the transition between formants is unnaturally smooth, and the high-frequency vocal tract friction (fricatives like “s” and “f”) is poorly reconstructed.
Forensic Conclusion
The forensic metrics overwhelmingly indicate that Sample A is a genuine acoustic recording of a human voice in a physical space, characterised by natural biometric perturbations, physiological breath markers, and spatial phase scattering. Sample B is highly consistent with AI generated synthetic speech (Deepfake/TTS), evidenced by its 10 kHz frequency cutoff, static noise floor, lack of respiratory artifacts, and unnaturally stable jitter, shimmer, and phase coherence
Virality
The viral claim was shared here, here, and here on X.
On Facebook, it was shared here, here, and here.
On Instagram, it was shared here.
Conclusion:
The video is a deepfake based on Soch Fact Check’s audio and visual analysis of . Netanyahu did not express support for Afghanistan or say that he considers Afghan Taliban’s supreme leader Hibatullah Akhundzada as Israel’s partner.